La frontera entre la voz humana y la creación artificial acaba de dar otro salto. En Japón, el creador digital Baku ha logrado unir tres herramientas potentes para generar una experiencia audiovisual de alto impacto: música original, voz sintética y una animación facial que no solo canta, sino que parece sentir lo que canta.
El experimento, publicado en Note.com, nos lleva a repensar no solo la autoría en la era de la IA, sino el papel del cuerpo, del rostro y de la emoción en el arte digital. Esto ya no es una simple voz artificial ni un avatar que se mueve. Es algo más: una performance digital que podría competir con artistas reales.
🎼 Etapas del proceso creativo
- Composición musical con Suno v4
Usando el prompt “mellow cute chip tune, female husky vocals”, Baku generó una canción que recuerda al estilo chipwave, con tintes kawaii y vocales suaves. Suno no solo compone: también interpreta, y eso abre la puerta a la voz como materia prima audiovisual. - Separación vocal con ClearVoice
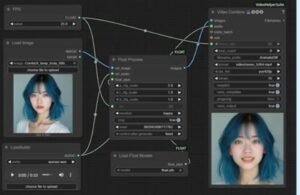
Para que la animación facial no tuviera ruidos de fondo ni instrumentales, separó la pista vocal usando herramientas como ClearVoice, logrando una señal limpia que sirviera como guía para la IA. - Sincronización de rostro con FLOAT + ComfyUI
Aquí es donde ocurre la magia. FLOAT, un modelo de retrato animado, recibió como entrada la pista de voz y generó una cara que se mueve, parpadea, interpreta y canta, fotograma a fotograma. Todo fue orquestado dentro del entorno visual de ComfyUI.
⚙️ Detalles técnicos relevantes
- Resolución del video generado: 512×512 px.
- Licencia de uso: FLOAT se distribuye bajo Creative Commons BY-NC 4.0 (no comercial).
- Compatibilidad idiomática: Aunque FLOAT fue entrenado con datos en inglés, la animación se comportó sorprendentemente bien en japonés.
- Hardware usado:
- GPU 4080 (16 GB): ~70 segundos para renderizar 30 segundos de video.
- GPU A100 (80 GB) en Vast.ai: canción completa (~2:30 minutos) procesada en menos de 3 minutos.
🧠 ¿Por qué esto importa?
Porque el experimento de Baku no es un truco visual ni una demo efímera. Es una demostración clara de cómo los modelos generativos están convergiendo: audio, imagen, movimiento y emoción se funden para crear experiencias profundamente humanas desde código.
Y aunque aún existen límites —resolución, licencia, control creativo fino—, lo que hemos visto es suficiente para imaginar un futuro donde:
surgen rostros virtuales con carisma capaces de conectar emocionalmente con audiencias reales.
cualquier persona puede crear su videoclip completo sin estudio de grabación ni cámara.
nacen nuevos géneros musicales y audiovisuales hechos por creadores solitarios o incluso directamente por IAs.
🔗 Enlace original del experimento: note.com/bakushu
🖤 En la sombra, lo que canta no siempre tiene pulmones.



